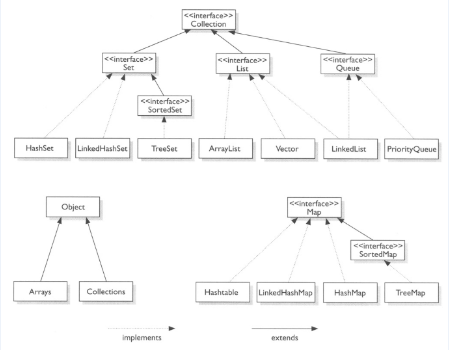
再来一张更为详细的图: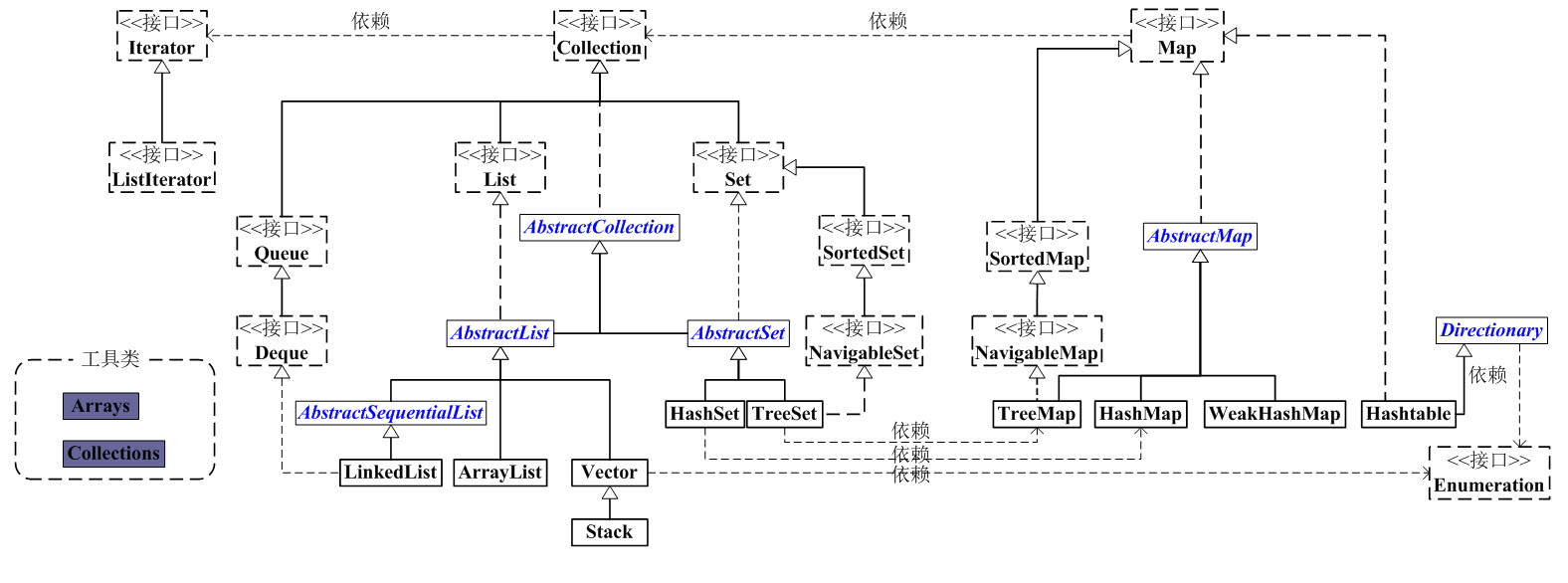
Collection和Collections的区别
Collection
上图可以看出,Collection是java中基础的集合接口,这个接口包括了下面一系列的抽象方法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15boolean add(E e);
boolean addAll(Collection<? extends E> c);
void clear();
boolean contains(Object o);
boolean containsAll(Collection<?> c);
boolean equals(Object o);
int hashCode();
boolean isEmpty();
Iterator<E> iterator();
boolean remove(Object o);
boolean removeAll(Collection<?> c);
boolean retainAll(Collection<?> c);
int size();
Object[] toArray();
<T> T[] toArray(T[] a);
Collections
Collections是一个工具类,提供了一系列静态的操作集合的方法,其中重要的包括:1
2
3
4
5
6......
static <T> int binarySearch(List<? extends Comparable<? super T>> list, T key); // 二分搜索
static <T> void copy(List<? super T> dest, List<? extends T> src); // 拷贝
static void reverse(List<?> list); // 反转
static <T extends Comparable<? super T>> void sort(List<T> list); // 排序
......
List
List是一个有序的队列,每一个元素都有它的索引。第一个元素的索引值是0。
List的实现类有LinkedList, ArrayList, Vector, Stack。
ArrayList与LinkedList的区别
ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。
插入元素
LinkedList
LinkedList.java中向指定位置插入元素的代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35// 在index前添加节点,且节点的值为element
public void add(int index, E element) {
addBefore(element, (index==size ? header : entry(index)));
}
// 获取双向链表中指定位置的节点
private Entry<E> entry(int index) {
if (index < 0 || index >= size)
throw new IndexOutOfBoundsException("Index: "+index+
", Size: "+size);
Entry<E> e = header;
// 获取index处的节点。
// 若index < 双向链表长度的1/2,则从前向后查找;
// 否则,从后向前查找。
if (index < (size >> 1)) {
for (int i = 0; i <= index; i++)
e = e.next;
} else {
for (int i = size; i > index; i--)
e = e.previous;
}
return e;
}
// 将节点(节点数据是e)添加到entry节点之前。
private Entry<E> addBefore(E e, Entry<E> entry) {
// 新建节点newEntry,将newEntry插入到节点e之前;并且设置newEntry的数据是e
Entry<E> newEntry = new Entry<E>(e, entry, entry.previous);
// 插入newEntry到链表中
newEntry.previous.next = newEntry;
newEntry.next.previous = newEntry;
size++;
modCount++;
return newEntry;
}
可以看到,往LinkedList里面插入元素的时候,要先在双向列表中找到插入节点的index,然后再插入。
这里也可以看到,java用了一个双向列表,这样,查找元素的时候,若index < 双向链表长度的1/2,则从前向后查找; 否则,从后向前查找,以此来提升性能。
所以LinkedList中插入元素很快,同理,删除也很快。
ArrayList
ArrayList.java中向指定位置插入元素的代码如下:1
2
3
4
5
6
7
8
9
10
11
12// 将e添加到ArrayList的指定位置
public void add(int index, E element) {
if (index > size || index < 0)
throw new IndexOutOfBoundsException(
"Index: "+index+", Size: "+size);
ensureCapacity(size+1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
可以看到,里面有个ensureCapacity(size + 1)操作,作用是确认ArrayList的容量,若容量不够,则增加容量。
System.arraycopy(elementData, index, elementData, index + 1, size - index);这个操作是耗时所在,它会移动index后的所有元素。
所以ArrayList中插入元素很慢,同理,删除也很慢
查询元素
LinkedList
看看LinkedList随机访问的代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23// 返回LinkedList指定位置的元素
public E get(int index) {
return entry(index).element;
}
// 获取双向链表中指定位置的节点
private Entry<E> entry(int index) {
if (index < 0 || index >= size)
throw new IndexOutOfBoundsException("Index: "+index+
", Size: "+size);
Entry<E> e = header;
// 获取index处的节点。
// 若index < 双向链表长度的1/2,则从前先后查找;
// 否则,从后向前查找。
if (index < (size >> 1)) {
for (int i = 0; i <= index; i++)
e = e.next;
} else {
for (int i = size; i > index; i--)
e = e.previous;
}
return e;
}
可以看到,在LinkedList中查找元素的时候,要先找到它的index,再去获取。
虽然有双向链表的加速,但在LinkedList中查找元素很慢。
ArrayList
ArrayList中随机访问的代码如下:1
2
3
4
5
6
7
8
9
10
11
12// 获取index位置的元素值
public E get(int index) {
RangeCheck(index);
return (E) elementData[index];
}
private void RangeCheck(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(
"Index: "+index+", Size: "+size);
}
可以看到,查找元素的时候,直接返回数组中index位置的元素,不需要向LinkedList一样查找。
所以在ArrayList中查找元素很快。
区别
由于底层数据结构的不同,两者的区别是:
- 对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针
- 对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据
ArrayList和Vector的区别
相同点
都是List
两者都继承自AbstractList,并且实现List接口:1
2
3
4
5
6
7// ArrayList的定义
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
// Vector的定义
public class Vector<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable {}
都实现了RandomAccess和Cloneable接口
实现RandomAccess接口,意味着它们都支持快速随机访问。
实现Cloneable接口,意味着它们能克隆自己。
都是通过数组实现的,本质上都是动态数组
两者都定义了数组elementData用于保存元素:1
2
3
4
5// 保存ArrayList中数据的数组
private transient Object[] elementData;
// 保存Vector中数据的数组
protected Object[] elementData;
默认数组容量是10
创建ArrayList或Vector时,如果没指定容量大小,则使用默认容量大小10:1
2
3
4
5
6
7
8
9// ArrayList构造函数。默认容量是10。
public ArrayList() {
this(10);
}
// Vector构造函数。默认容量是10。
public Vector() {
this(10);
}
都支持Iterator和listIterator遍历
都继承于AbstractList。
而AbstractList中分别实现了:iterator
- iterator()接口,返回Iterator迭代器
- listIterator()接口,返回ListIterator迭代器
不同之处
线程安全性不同
ArrayList是非线程安全。
而Vector是线程安全的,它的函数都是synchronized的,即都是支持同步的。
ArrayList适用于单线程,Vector适用于多线程。
对序列化支持不同
ArrayList支持序列化,而Vector不支持。
因为ArrayList有实现java.io.Serializable接口,而Vector没有实现该接口。
容量增加方式不同
逐个添加元素时,若ArrayList容量不足时,新的容量 = (原始容量x3)/2 + 1。
而Vector的容量增长与增长系数有关。
若指定了增长系数,且增长系数有效(即,大于0),那么每次容量不足时,新的容量=原始容量+增长系数。
若增长系数无效(即,小于/等于0),新的容量=原始容量 x 2。
ArrayList中容量增长的主要函数如下:1
2
3
4
5
6
7
8
9
10
11
12
13public void ensureCapacity(int minCapacity) {
// 将“修改统计数”+1
modCount++;
int oldCapacity = elementData.length;
// 若当前容量不足以容纳当前的元素个数,设置 新的容量=“(原始容量x3)/2 + 1”
if (minCapacity > oldCapacity) {
Object oldData[] = elementData;
int newCapacity = (oldCapacity * 3)/2 + 1;
if (newCapacity < minCapacity)
newCapacity = minCapacity;
elementData = Arrays.copyOf(elementData, newCapacity);
}
}
Vector中容量增长的主要函数如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15private void ensureCapacityHelper(int minCapacity) {
int oldCapacity = elementData.length;
// 当Vector的容量不足以容纳当前的全部元素,增加容量大小。
// 若 容量增量系数>0(即capacityIncrement>0),则将容量增大当capacityIncrement
// 否则,将容量增大一倍。
if (minCapacity > oldCapacity) {
Object[] oldData = elementData;
int newCapacity = (capacityIncrement > 0) ?
(oldCapacity + capacityIncrement) : (oldCapacity * 2);
if (newCapacity < minCapacity) {
newCapacity = minCapacity;
}
elementData = Arrays.copyOf(elementData, newCapacity);
}
}
对Enumeration的支持不同
Vector支持通过Enumeration去遍历,而List不支持。
Vector中实现Enumeration的代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21public Enumeration<E> elements() {
// 通过匿名类实现Enumeration
return new Enumeration<E>() {
int count = 0;
// 是否存在下一个元素
public boolean hasMoreElements() {
return count < elementCount;
}
// 获取下一个元素
public E nextElement() {
synchronized (Vector.this) {
if (count < elementCount) {
return (E)elementData[count++];
}
}
throw new NoSuchElementException("Vector Enumeration");
}
};
}
Set
Set是一个不允许有重复元素的集合。
Set的实现类有HastSet和TreeSet,同时HashSet还有一个子类LinkedHashSet。
HashSet依赖于HashMap,它实际上是通过HashMap实现的;
TreeSet依赖于TreeMap,它实际上是通过TreeMap实现的。
HashSet、LinkedHashSet、TreeSet使用区别
- HashSet:哈希表是通过使用称为散列法的机制来存储信息的,元素并没有以某种特定顺序来存放;
- LinkedHashSet:以元素插入的顺序来维护集合的链接表,允许以插入的顺序在集合中迭代;
- TreeSet:提供一个使用树结构存储Set接口的实现,对象以升序顺序存储,访问和遍历的时间很快。
所以,简单地说,如果我们想要一个快速的set,那么我们应该使用HashSet;如果我们需要一个已经排好序的set,那么TreeSet应该被使用;如果我们想一个可以根据插入顺序来读取的set,那么LinkedHashSet应该被使用。