Hash
Hash(哈希),也称为散列,是一类算法的统称。
Hash函数的主要作用是将数据转换为一个Hash值,方便数据的存储,查询。
因为一般Hash函数的输入是任意长度,而输出是固定长度的,所以,Hash也被认为是一种压缩映射,可以理解为Hash函数将数据压缩成了固定长度的消息摘要。
Hash函数是一种典型以空间换时间的算法,一般用于快速查找和加密算法。
常见的Hash函数
直接定址
取关键字或关键字的某个线性函数。
数字分析
分析关键字,取其中冲突不大的数位,常见于知道全部关键字的情况,比如取生日数据的后几位。
平方取中
取关键字平方后的中间几个数位。
常见于不知道关键字全部情况时,取其中任意的几个数位都不合适,而平方后中间几个数位同每一位都相关。
折叠
将关键字分割成位数相同的几部分(最后一部分的位数可以不同),然后取这几部分的叠加和(舍去进位)作为哈希地址。
取模
取关键字被某个不大于哈希表表长的数除后所得余数为哈希地址。
随机数
选择一个随机函数,取关键字的随机函数值为它的哈希地址。
哈希表
哈希表,就是根据关键码(key)的Hash值进行直接访问的数据结构。
简单来说,给定表T,对于任意关键字k,将其值(value)存放到f(k)的存储位置,其中,f是Hash函数,T称为哈希表。
这样,下次去查找这个值的时候,便可以直接定位了。
上一篇提到,数组的特点是寻址容易,但插入和删除困难(典型的是ArrayList),而链表的特点是插入和删除容易,但是寻址困难(典型的是LinkedList),而哈希表的特点就是寻址容易,插入和删除也容易来 。
碰撞
如果不同的关键字,通过Hash函数取到的Hash值相同,即k1!=k2,但f(k1)=f(k2),这种情况就叫做碰撞(也叫冲突,英文Collision)。
无论Hash函数涉及的多么精妙,碰撞都是不可避免的。
下面是一些常见的处理碰撞的方法:
再散列法
同义词产生地址冲突时计算另一个散列函数地址,直到冲突不再发生,这种方法不易产生“聚集”,但增加了计算时间。
开放定址法
开放定址法解决冲突的方法是:当冲突发生时,使用某种探测技术在散列表中形成一个探测序列。
沿此序列逐个单元地查找,直到找到给定的关键字,或者碰到一个开放的地址(即该地址单元为空)为止。
- 若要插入,在探查到开放的地址,则可将待插入的新结点存入该地址单元
- 查找时探查到开放地址则表明表中无待查的关键字,即查找失败
用开放定址法建立散列表时,建表前须将表中所有单元(更严格地说,是指单元中存储的关键字)置空。
按照形成探查序列的方法不同,可将开放定址法区分为线性探查法、线性补偿探测法、随机探测等。
线性及线性补偿
将散列表T[0..m-1]看成是一个循环向量,若初始探查的地址为d(即h(key)=d),则最长的探查序列为:
d,d+l,d+2,…,m-1,0,1,…,d-1。
简单来说,就是探查时从地址d开始,首先探查T[d],然后依次探查T[d+1],…,直到T[m-1],此后又循环到T[0],T[1],…,直到探查到T[d-1]为止。
线性补偿就是将线性探测的步长从 1 改为 Q ,即将上述算法中的 j = (j + 1) % m 改为: j = (j + Q) % m ,而且要求 Q 与 m 是互质的,以便能探测到哈希表中的所有单元。
二次探测散列
将探测的步长改为“1, -1, 4, -4, 9, -9……kk, -kk”,其中,k <= m / 2。
随机探测
将线性探测的步长从常数改为随机数,即令: j = (j + RN) % m ,其中 RN 是一个随机数。
在实际程序中应预先用随机数发生器产生一个随机序列,将此序列作为依次探测的步长。这样就能使不同的关键字具有不同的探测次序,从而可以减少堆聚。
拉链法
拉链法解决冲突的方法是:将所有关键字为同义词的结点链接在同一个单链表中。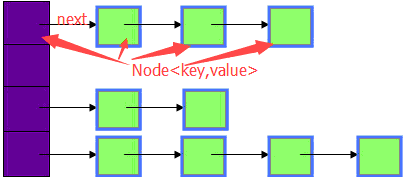
与开放定址法相比,拉链法有如下几个优点:
- 链接法处理冲突简单,且无堆积现象,即非同义词决不会发生冲突,因此平均查找长度较短;
- 由于链接法中各链表上的结点空间是动态申请的,故它更适合于造表前无法确定表长的情况;
- 开放定址法为减少冲突,要求装填因子α较小,故当结点规模较大时会浪费很多空间。而链接法中可取α≥1,且结点较大时,拉链法中增加的指针域可忽略不计,因此节省空间;
- 在用链接法构造的散列表中,删除结点的操作易于实现。只要简单地删去链表上相应的结点即可。
而对开放地址法构造的散列表,删除结点不能简单地将被删结点的空间置为空,否则将截断在它之后填人散列表的同义词结点的查找路径。
这是因为各种开放地址法中,空地址单元(即开放地址)都是查找失败的条件。
因此在 用开放地址法处理冲突的散列表上执行删除操作,只能在被删结点上做删除标记,而不能真正删除结点。
当然,链接法也有其缺点:
- 指针需要额外的空间,故当结点规模较小时,开放定址法较为节省空间;
- 若将节省的指针空间用来扩大散列表的规模,可使装填因子变小,这又减少了开放定址法中的冲突,从而提高平均查找速度。
查找性能
哈希表大小的确定非常关键,如果Hash表的空间远远大于最后实际存储的记录个数,则造成了很大的空间浪费,如果选取小了的话,则容易造成冲突。
在实际情况中,一般需要根据最终记录存储个数和关键字的分布特点来确定Hash表的大小。
但是一种情况时可能事先不知道最终需要存储的记录个数,则需要动态维护Hash表的容量,此时可能需要重新计算Hash地址。
而哈希表的大小也直接影响了哈希表的平均查找长度。
查找过程中,关键码的比较次数,取决于产生冲突的多少,产生的冲突少,查找效率就高,产生的冲突多,查找效率就低。
影响产生冲突多少有以下三个因素:
- 散列函数是否均匀
- 处理冲突的方法
- 散列表的装填因子
这就涉及到一个概念——装填因子。
装填因子=表中的记录数/哈希表的长度。
如果装填因子越小,表明表中还有很多的空单元,则发生冲突的可能性越小;而装填因子越大,则发生冲突的可能性就越大,在查找时所耗费的时间就越多。
有相关文献证明当装填因子在0.5左右的时候,Hash的性能能够达到最优。
java中的HashMap
Map是一个映射接口,即key-value键值对。
Map中的每一个元素包含“一个key”和“key对应的value”。
HashMap实现了Map接口,继承AbstractMap。1
2
3public class HashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable
构造函数
HashMap提供了三个构造函数:1
2
3HashMap() // 构造一个具有默认初始容量(16)和默认加载因子(0.75)的空HashMap。
HashMap(int initialCapacity) // 构造一个带指定初始容量和默认加载因子(0.75)的空HashMap。
HashMap(int initialCapacity, float loadFactor) // 构造一个带指定初始容量和加载因子的空HashMap。
可以看到,构造函数涉及两个重要的参数,容量以及加载因子。
如果“(HashMap中存储的记录 / 当前容量) > 加载因子”,那么,HashMap就会进行自增。
具体代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25public HashMap(int initialCapacity, float loadFactor) {
//初始容量不能<0
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: "
+ initialCapacity);
//初始容量不能 > 最大容量值,HashMap的最大容量值为2^30
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//负载因子不能 < 0
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: "
+ loadFactor);
// 计算出大于 initialCapacity 的最小的 2 的 n 次方值。
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
this.loadFactor = loadFactor;
//设置HashMap的容量极限,当HashMap的容量达到该极限时就会进行扩容操作
threshold = (int) (capacity * loadFactor);
//初始化table数组
table = new Entry[capacity];
init();
}
HashMap底层实现还是数组,只是数组的每一项都是一条链。
这也说明,java的HashMap是采用链接法去处理冲突的。
每次新建一个HashMap时,都会初始化一个table数组。table数组的元素为Entry节点。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
final int hash;
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
.......
}
其中Entry为HashMap的内部类,它包含了键key、值value、下一个节点next,以及hash值。
存储(put)
1 | public V put(K key, V value) { |
可以看大HashMap保存数据的过程为:
首先判断key是否为null,若为null,则直接调用putForNullKey方法。
若不为空则先计算key的hash值,然后根据hash值搜索在table数组中的索引位置,如果table数组在该位置处有元素,则通过比较是否存在相同的key,若存在则覆盖原来key的value,否则将该元素保存在链头(最先保存的元素放在链尾)。
若table在该处没有元素,则直接保存。
看这里面的Hash函数:1
2
3
4static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
太复杂,看不懂。
再来看获取地址的方法:1
2
3static int indexFor(int h, int length) {
return h & (length-1);
}
记得在构造函数中,有一行capacity <<= 1,这就保证了HashMap的底层数组长度为2的n次方,这个时候,h & (length-1)就相当于对length取模。
接着看插入节点的代码:1
2
3
4
5
6
7
8
9void addEntry(int hash, K key, V value, int bucketIndex) {
//获取bucketIndex处的Entry
Entry<K, V> e = table[bucketIndex];
//将新创建的 Entry 放入 bucketIndex 索引处,并让新的 Entry 指向原来的 Entry
table[bucketIndex] = new Entry<K, V>(hash, key, value, e);
//若HashMap中元素的个数超过极限了,则容量扩大两倍
if (size++ >= threshold)
resize(2 * table.length);
}
可以看到,每次都是将新插入的元素放在链头。同时,若HashMap中元素的个数超过极限,就会进行扩容。
获取(get)
相对于存储而言,获取比较简单,通过key的hash值找到在table数组中的索引处的Entry,然后返回该key对应的value即可:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15public V get(Object key) {
// 若为null,调用getForNullKey方法返回相对应的value
if (key == null)
return getForNullKey();
// 根据该 key 的 hashCode 值计算它的 hash 码
int hash = hash(key.hashCode());
// 取出 table 数组中指定索引处的值
for (Entry<K, V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) {
Object k;
//若搜索的key与查找的key相同,则返回相对应的value
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
其他Map
HashTable
在Java类库中出现的第一个关联的集合类是Hashtable,它是JDK 1.0的一部分。
Hashtable提供了一种易于使用的、线程安全的、关联的map功能,这当然也是方便的。
然而,线程安全性是凭代价换来的——Hashtable的所有方法都是同步的。
Hashtable的后继者HashMap是作为JDK1.2中的集合框架的一部分出现的,它通过提供一个不同步的基类和一个同步的包装器Collections.synchronizedMap,解决了线程安全性问题。
所以说HashTable和HashMap存在很多的相同点,都是基于“拉链法”实现的散列表。
主要区别在于:
- HashTable基于Dictionary类,而HashMap是基于AbstractMap
- HashMap可以允许存在一个为null的key和任意个为null的value,但是HashTable中的key和value都不允许为null
- Hashtable的方法是同步的,而HashMap的方法不是
- HashTable使用Enumeration,HashMap使用Iterator
- HashTable中hash数组默认大小是11,增加的方式是 old*2+1。HashMap中hash数组的默认大小是16,而且一定是2的指数
- HashTable直接使用对象的hashCode,而HashMap重新计算hash值
HashTable的同步
HashTable容器使用synchronized来保证线程安全,但在线程竞争激烈的情况 下HashTable的效率非常低下。
因为当一个线程访问HashTable的同步方法时,其他线程访问HashTable的同步方法时,可能会进入阻塞 或轮询状态。
如线程1使用put进行添加元素,线程2不但不能使用put方法添加元素,并且也不能使用get方法来获取元素,所以竞争越激烈效率越低。
总的来说,HashTable是一个java中早期的近乎废弃的哈希表。
LinkedHashMap
LinkedHashMap 是 HashMap 的一个子类,它保留插入的顺序,如果需要输出的顺序和输入时的相同,那么就选用 LinkedHashMap。
简单来说,LinkedHashMap是一个有序的HashMap。
LinkedHashMap在HashMap的基础上维护着一个运行于所有条目的双重链接列表,此链接列表定义了迭代顺序,该迭代顺序可以是插入顺序或者是访问顺序。
LRU缓存
LRU是Least Recently Used的缩写,就是最近最少使用。
也就是说,LRU 缓存把最近最少使用的数据移除,让给最新读取的数据。而往往最常读取的,也是读取次数最多的。
实现LRU缓存用到的数据结构就是LinkedHashMap。
关于LRU缓存会另讲。
TreeMap
java中的TreeMap是通过红黑树实现的。
该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的Comparator进行排序。1
2
3public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable {}
所以,如果要按自然顺序或自定义顺序遍历键,那么TreeMap会更好。
synchronizedMap
Collections工具类提供了两个静态方法——synchronizedMap和synchronizedList,注意,这两个被称为有条件的线程安全。
这是因为所有单个的操作都是线程安全的,但是多个操作组成的操作序列却可能导致数据争用,因为在操作序列中控制流取决于前面操作的结果。1
2
3
4// shm是SynchronizedMap的一个实例
if(shm.containsKey('key')) {
shm.remove(key);
}
这段代码用于从map中删除一个元素之前判断是否存在这个元素。
这里的containsKey和reomve方法都是同步的,但是整段代码却不是。
有这么一个场景:线程A执行了containsKey方法返回 true,准备执行remove操作;这时另一个线程B开始执行,同样执行了containsKey方法返回true,并接着执行了remove操作;然 后线程A接着执行remove操作时发现此时已经没有这个元素了。
要保证这段代码按我们的意愿工作,一个办法就是对这段代码进行同步控制,但是这么做付出的代价太大。
更好的选择:ConcurrentHashMap
util.concurrent包中的ConcurrentHashMap类(也将出现在JDK 1.5中的java.util.concurrent包中)是对Map的线程安全的实现,比起Hashtable以及synchronizedMap来,它提供了好得多的并发性。
Hashtable中采用的锁机制是一次锁住整个hash表,从而同一时刻只能由一个线程对其进行操作;而ConcurrentHashMap中则是一次锁住一个桶。
ConcurrentHashMap默认将hash表分为16个桶,诸如get,put,remove等常用操作只锁当前需要用到的桶。
这样,原来只能一个线程进入,现在却能同时有16个写线程执行,并发性能的提升是显而易见的。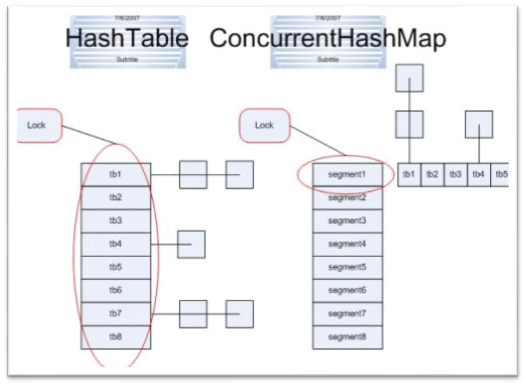
上面说到的16个线程指的是写线程,而读操作大部分时候都不需要用到锁。
只有在size等操作时才需要锁住整个hash表。
在迭代方面,ConcurrentHashMap使用了一种不同的迭代方式。
在这种迭代方式中,当iterator被创建后集合再发生改变就不再是抛出ConcurrentModificationException,取而代之的是在改变时new新的数据从而不影响原有的数据,iterator完成后再将头指针替换为新的数据,这样iterator线程可以使用原来老的数据,而写线程也可以并发的完成改变。